Face-Dubbing++: Lip-synchronous, voice preserving translation of videos
Published in 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), 2023
Recommended citation: A. Waibel et al., "Face-Dubbing++: LIP-Synchronous, Voice Preserving Translation Of Videos," 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), Rhodes Island, Greece, 2023, pp. 1-5, doi: 10.1109/ICASSPW59220.2023.10193719. https://ieeexplore.ieee.org/abstract/document/10193719
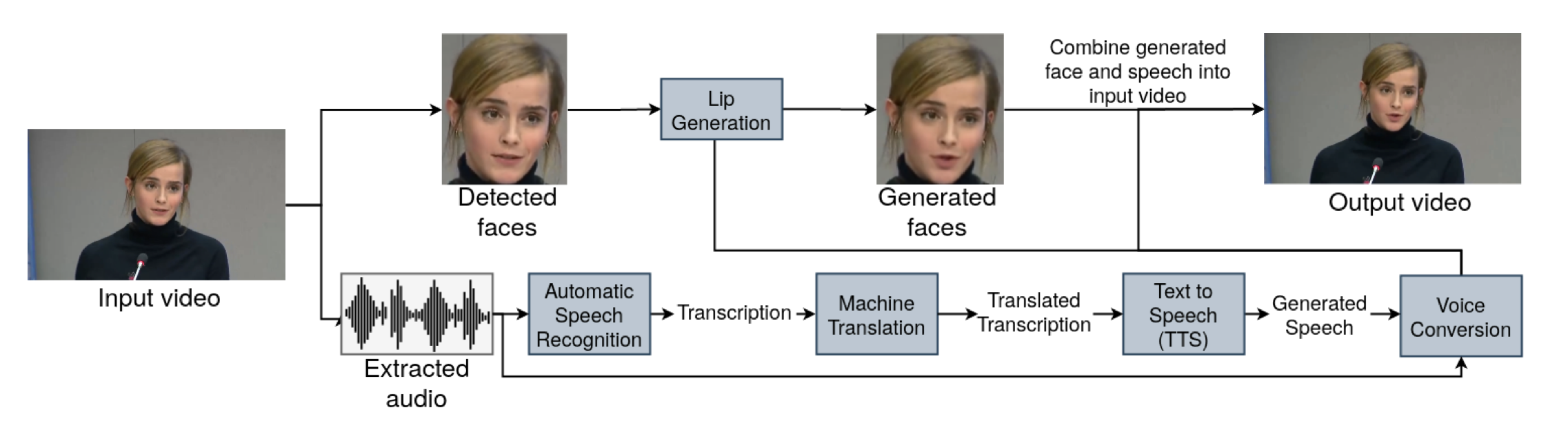
In this paper, we propose a neural end-to-end system for voice preserving and lip-synchronous video translation. The system is designed to combine multiple component models and produces a video of the original speaker speaking in the target language that is lip-synchronous with the target speech, yet maintains emphases in speech, voice characteristics, and face video of the original speaker. The result is a video of a speaker speaking in another language without actually knowing it.
Recommended citation: A. Waibel et al., “Face-Dubbing++: LIP-Synchronous, Voice Preserving Translation Of Videos,” 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), Rhodes Island, Greece, 2023, pp. 1-5, doi: 10.1109/ICASSPW59220.2023.10193719.